Automates finis (déterministes) et langages réguliers.
Parser
Grammaires hors contextes.
Parser descendant naïf
Peut avoir une complexité exponentielle + non déterministe en cas
d’ambiguités.
On va donc essayer de faire du parsing prédictif.
LL(k)
Il s’agit d’un parser descendant.
On regarde k caractères en avance ce qu’il y a en entrée, de sorte à
savoir quelle règle appliquer.
Quelques définitions :
Un symbole non terminal est nullable si
On appelle FIRST(y) l’ensemble des terminaux par
lesquels commencent y.
On appelle FOLLOW(y) l’ensemble des terminaux
pouvant suivre y.
On peut alors déterminer facilement par des régles récursives les
nullables, FOLLOW et FIRST de chaque non terminal.
On construit alors une table de parsing dans laquelle on place, pour
toute paire (NT, t)
Limites :
Pas de récursions gauches
Commencer par le même symbole à gauche est embêtant
LR(k) (left to
right parse, rightmost derivation)
Notations : T,t = terminal, NT = Non Terminal
Plus puissant.
Se base sur un automate à pile.
Il s’agit d’une analyse montante.
LR(0)
Parsing en 3 étapes :
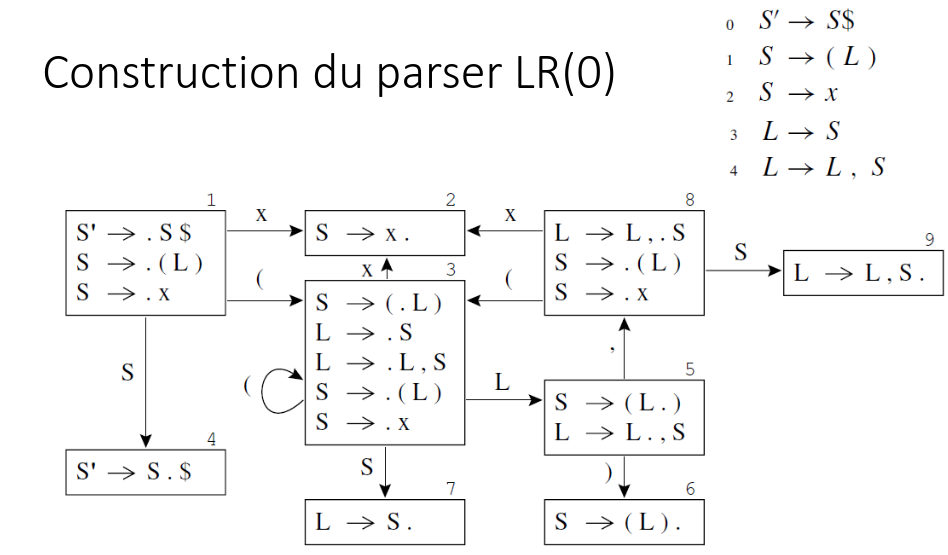
On commence par créer un automate, qui va nous permettre de créer
une table de parsing :
On pose un symbole spécial “.” marquant l’avancement dans le parsing
d’une règle.
On prend l’axiome, on place ses dérivations dans un état et on met
le “.” au début de la dérivation.
Pour chaque non terminal devant lequel est placé un point, on met
les dérivations de ce non terminal dans l’état correspondant.
On crée un transition entre deux état en déplaceant le “.” d’un vers
la droite, à supposer que le symbole de transition corresponde au
symbole consommé par le “.”.
Exemple :
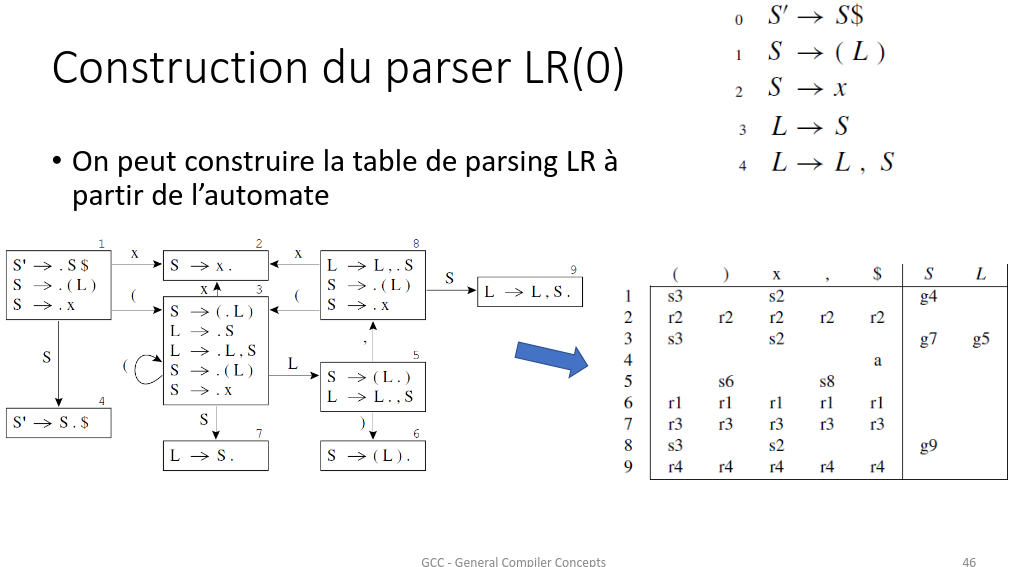
À partir de cet automate, on crée une table de parsing :
On place les non terminaux au début en indice de colonnes, les
termninaux en fin en indice de colonne. On place les état de l’automate
précédemment créé en indice des lignes.
Dans une case, on met :
r_i (reduce i) si le “.” est à la fin d’une règle, avec i le numéro
de la règle appliquée.
s_i (shift i) si on est dans une case (t, j), et qu’on peut aller
dans l’état i depuis l’état j sur une transition annotée t.
g_i (goto i) si on est dans une case (NT, j) et qu’on peut aller
dans l’état j depuis l’état i sur une transition annotée t.
Exemple :
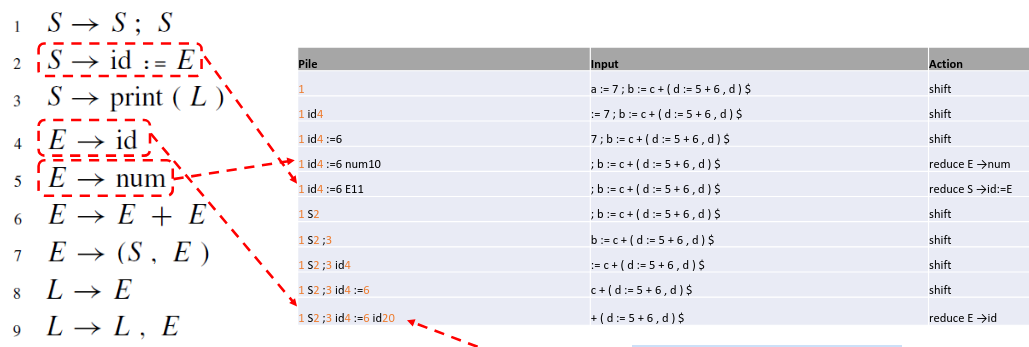
Parsing
On a une pile, sur laquelle on garde les symboles (terminaux ou non)
et les états dans lequel était l’automate quand le symbole a été
empilé.
On commence dans l’état \(1\).
Si on est dans l’état \(i\) et qu’on
lit le symbole terminal \(t\), on
regarde le contenu de la case de la table précédemment créée :
Si elle contient \(s_j\), on va
dans l’état \(j\), en pushant \(t i\) en haut de la pile.
Si elle contient $$
Exemple:
LR(1)
???
SLR
On supprime les transitions \(r_i\)
de la table si le terminal de la colonne n’est pas contenu dans \(FIRST(NT_i)\)
Analyse sémantique
Objectif : donner du sens à un programme en transformant l’entrée en
représentation intermédiaire utilisable par le middle-end, analysé les
erreurs de typages…
Approche 1 : Grammaire
attribuée
Une grammaire attribuée est une grammaire de
programme à laquelle on a rajouté :
des attributs aux symboles
des règles de calculs liées aux productions
On analyse ainsi un code parser en retournant un résultat à la racine
de l’arbre.
Exemple : Nombre binaire :
Exemple grammaire attribuée
addition
/!\ : Ordre d’évaluation important !
Différentes méthodes pour cette analyse :
Évaluation dynamique : on calcul dès que les opérandes sont
disponibles (besoin d’un graphe de dépendance).
Évaluation force brute : On répète des régles jusqu’à
convergence.
Évaluation par règles : Analyse statique des dépendances pour
déterminer l’ordre d’évaluation.
Si il y a un cycle… :
On les interdit
On évalue jusqu’à convergence
Approche 2 : Construction ad
hoc
Similaire aux grammaires attribuées (avec l’info que dans un sens),
on associe des actions à chaque production de la grammaire.
Gramaire LL : Quand les règles de productions sont appliquées
Grammaire LR : Lors des réductions, qui correspondent à
l’application d’une règle
Exemple : construction d’un AST.
AST (Abstract Syntax Tree) : Par
rapport à un CST (concrete syntax
tree, abre obtenu en créant l’abre de dérivation en appliquant
la grammaire), on supprime les non terminaux, on met les terminaux
“discriminants” / “importants”.
Design Pattern : Visiteurs
Le design pattern visiteurs correspond au parcours
d’un objet en appliquant un traitement spécifique à chaque élément.
RQ: Par rapport aux approches précédentes, ça revient à
appliquer les actions après que l’arbre n’ait été
construit.
Représentation intermédiaire
(IR)
Une représentation intérmediaire est la représentation interne du
compilateur.
Elle doit : - Être efficace - Abstraite (indépendante de
l’architecture)
Il en existe de nombreuses, avec leurs avantages et inconvénients,
certains compilateurs en utilisent plusieurs. (CompCert : 20 IR !)
Framework MLIR (Medium Level IR)
Permet de définir facilement des IR
Des niveau d’abstraction différent
structure d’IR similaire
Différents niveaux d’IR : Déjà
vus
CST
AST
DAG : version réduite de l’AST : Les sous expressions communes sont
réutilisées
Graphe de flot de contrôle (CFG)
:
Sous forme de graphe
Chaque noeud est un bloc de code
Arc : transfert de contrôle possible à l’éxecution
Unique bloc d’entrée et de sortie
Plusieurs granularités possibles :
Un noeud par statement
Un noeud par bloc de base (un flot unique, e.g. les séquences).
Bloc de base : Un point d’entrée, et un de
sortie.
Souvent représenté par AST ou DAG.
Construction du CFG :
Par visiteurs : On récupère pour les enfants si c’est un nouveau bloc
ou non : - Si s’en est un, il a un point d’entrée et de sortie, et on
s’y connecte pour créer le flot. - Sinon, on l’ajoute aux statements du
bloc.
Code du visitBlockStatement
Graphe de dépendance
Rep sous forme de graphe
Encode les dep de données entre le op
Un noeud pour chaque op
Un arch dès qu’une op utilise la donnée créée par une autre op
Plus compliqué quand il y a du controle
Souvent une IR
Machine à pile
Représentation linéaire
Encode l’éxecution sur une machine à pile
Utilisée par Java
Code 3 adresses
Représentation linéaire
Encode l’éxecution sur une machine à registre
Instructions + ou - proche de l’assembleur de la machine
Forme SSA (Single Static
Assignment)
Les variables ne sont assignées qu’une seule fois
Des opérations spéciales permettent de choisir une valeur parmis
plusieurs possibles (\(\Phi\), dans les
flots de contrôle)
Propriété de \(\Phi\)
\(\Phi\) a une arité égale au nombre
de prédecesseur. On choisit l’opérande selon le bloc éxecuté
précédemment.
Construction
Idée :
Quand on est sur un branchement, on crée une variable assignée par
un phi d’opérande les variables correspondantes des blocs
prédécesseurs.
Sinon, on récupère juste la variable précédente.
Pour ce faire, il faut assigner un nom unique aux valeurs d’un bloc
de base :
Local Value Numbering : Assignation d’un nom unique
aux valeurs d’un bloc de base.
On utilise un tableau currentDef qui associe les valeurs SSA dans un
bloc donné.
Puis, il faut faire de même avec les \(\Phi\), c’est ce qu’on appelle le
Global Value Numbering.
Ça nous donne l’algo suivant :
Code du readVaraibleRec
RQ :
Algo non optimal, mais en général c’est OK.
On peut éliminer les \(\Phi\)
instructions triviales : \(v_i := \Phi (v_i,
v, v) \rightarrow v\)
CF : Braun & al, “Simple and efficient
construciton of SSA Form”, 2013
PB : On veut construire la forme SSA en même temps que le CFG.
\(\rightarrow\) sur un CFG partiel,
issu de la transformation AST \(\rightarrow\) IR.
Ce CFG n’est pas complet, un bloc peut avoir de nouveaux
prédécesseurs plus tard (boucles)
On définit ainsi deux types de blocs :
Les blocs filled : Le local value
numbering a été effectué sur le bloc. Seul ces blocs peuvent avoir
un successeur.
Les blocs sealed : Tous ses prédécesseurs ont été
trouvés.
Les phi insérés dans les blocs non sealed sont laissés sans
opérandes et stockés dans une liste au niveau du bloc.
Quand un block est marqué comme sealed, on résout les phi non
résolus.
Optimisations
Objectifs
Plusieurs critères : rapide, petit,…
Pas de garanties : améliorations en moyenne
Nécessité de conserver la sémantique
Quelques exemples
d’équations dataflow
Liveness Analysis
Détermine où une variable est en vie dans un programme.
On dit qu’une variable est :
live s’il y a un chemin direct vers un use
sans rencontrer de def.
live-in sur un noeud si est live sur au moins un
arc menant à ce noeud.
live-out sur un noeud si est live sur au moins un
arc sortant de ce noeud.
C’est l’algo le plus efficace pour résoudre les équations
dataflow.
Transformations
Élimination de sous
expressions communes
Quand s : t := x + y est available, on calcule
le reaching expression sur le statement, on assigne ce
statement à une variable temporaire et on remplace le statement par
cette variable temporaire.