2026 - 03 - 23
PB : Comment vérifier qu’un logiciel fonctionne ?
Pourquoi :
Comment :
Exemple de bugs connus : …
Méthodes formelles : Raisonnement rigoureux, parfois exhaustif, et (semi) automatisé pour garantir l’absence de bugs.
On a aussi utilisé des méthodes “informelles”. Ça passe mal à l’échelle.
Et les méthodes 100% automatiques n’existent pas (indécidabilité de Riesz).
Il y a donc différents niveaux d’automatisation :
| Méthode | Spécification | Preuve | Verdict |
|---|---|---|---|
| Preuve assistée par ordi | Manuelle, avec HOL | Semi manuelle | QED / ? |
| Preuve automatique | Semi manuelle, logique ordre 1 | Automatique | QED / inf / ? |
| Analyse statique | Automatique | Automatique | QED / ? |
| Modèle checking | Formule en logique temporelle | Automatique | QED / Contre Exemple |
(F* : types incluent logique d’ordre 1)
| Compétences | Développées | Prérequis |
|---|---|---|
| Spécifier & prouver | + | ++ |
| Algorithmique | ++ | + (SAT) |
| Programmation | ++ | + (OCaml) |
| Sémentique langages | + (SEM) | |
| Preuve par induction | ++ | + (ind) |
| Théorie des modèles | ++ | + (L3) |
CM / TD / TP mélangés
Prouver qu’un programme est correct nécessite de spécifier ce que correct signifie.
Exemple :
s = 0
k = 0
while k < N:
s += k
k += 1Que fait ce programme ? Il calcule la somme des N - 1 premiers entiers : 0 + ... + (N - 1) = N (N - 1).
SI N \geq 0 !
Il faut faire attention aux préconditions…
Ici, on va utiliser plusieurs outils.
Informellement, \left< P \right> c \left< Q \right> signifie :
Si on exécute le programme c en partant d’un état initial vérifiant l’état P, alors la post condition Q est vérifiée à la fin de l’exécution, si c termine.
RQ : Il s’agit de correction partielle : ça fonctionne si c termine.
On peut aussi utiliser un critère plus fort de correction totale :
[P] c [Q] signifie la même chose, avec la garantie en plus que c termine sur l’exécution à partir d’état initiaux satisfaisant P.
Exemples :
# x & y des references
def swap(x,y):
z = x
x = y
y = zTriplet de hoare correspondant :
\left<x = a \land y = b \right> swap \left< x = b \land y = a \right>
Avec a et b des variables “fantômes” non libre dans la commande.
c ::= skip
| x := t
| c1; c2
| if t then c1 else c2
| while t do cOn dit que t est un terme, par exemple : x y z 1 3.14 -x -(x+1) sin(x)
Rappels de logique
F ::= <atome>
| not F
| F1 and F2
| F1 or F2
| F1 => F2
| F1 <=> F2
| exists x. F
| forall x. FExercice :
Si, \left< P1 \right> c \left< Q1 \right> et \left< P2 \right> c \left< Q2 \right>, Peut on affirmer :
Correction : Les deux sont vraies.
La logique de Hoare est un sytème déductif de logique de programme. On la définit inductivement (les formules suivantes sont vraies) :
Pour éviter d’avoir à écrire des triplets \left< P \right> c \left< Q \right>, et les arbres de dérivations correspondant, on va annoter les programmes avec des assertion intermédiaires.
Exemple :
<y = a> => <I[0/x]>
x := 0
<I>
while y > 0 do
<I /\ y > 0> => <I[(x+1)/x][(y+1)/y]>
y := y - 1
<I[(x+1)/x]>
x := x + 1
<I>
<I /\ not y > 0> => <x = a \/ a < 0>On va définir la syntaxe suivante pour ces programmes “augmentés” :
d ::= skip<Q>
| x := e<Q>
| d; d
| if b do <P1> c1 else <P2> c2 <Q>
| while b do <P> c <Q>
| => <P> d
| d => <Q>
dc ::= <P> dOn définit par ailleurs les 3 fonctions eff,
pre et post suivantes, définit inductivement
:
eff(<P> d) = eff(d)
eff(skip <Q>) = skip
eff(x := e <Q>) = x := e
eff(while b do <P> c Q) := while b do eff(c)
pre(<P> d) = P
post(<P> d) = post(d)
post(skip <Q>) = Q
post(while b do <P> c <Q>) = Q
post(c1; c2) = post(c2)L’intuition est que \left< P \right> d est valide ssi \left< P \right> \text{eff}(d) \left< \text{post}(Q) \right>.
\left< P \right> d est dit valide ssi P \vdash d avec \cdot \vdash \cdot définit inductivement par :
RQ : Ce système est totalement dirigé par la syntaxe <3
Mais : Correction, completude… ?
Correction : Si \left< P \right> d est valide alors \left< P \right> \text{eff}(d) \left< \text{post}(d) \right>
Preuve :
On procède par induction sur d.
On note \mathbf{P}(d) := \forall P, \left< P \right> d \implies \left< P \right> \text{ eff}(d) \left< \text{ post}(d) \right>
Principe d’induction :
Si :
Alors \forall d, \mathbf{P}(d).
Retour à la preuve :
On traite uniquement le cas ‘skip’ ici :
Soit d_1, d_2, supposons que \mathbf{P}(d_1) et \mathbf{P}(d_2).
Soit P tq P \vdash d_1;d2.
Montrons que \left< P \right> \text{eff}(d_1);\text{eff}(d_2) \left< \text{post}(d_2) \right>
Complétude :
La proposition suivante est vraie \forall P,c,Q :
\mathbf{P}(P, c, Q) :=
“Si \left< P \right> c \left< Q
\right>, il existe d tel que
:
On fait la preuve par induction sur \left< P \right> c \left< Q \right>.
Principe d’induction :
Si :
Alors : \forall P, c, Q, \left< P \right> c \left< Q \right> \implies \mathbf{P}(P,c,Q).
Retour à la preuve (uniquement le cas 5) :
Appelons d' tq c=\text{while } b \text{ do } c'
Considérons d = \text{while } b \text{ do } \left< I \land b \right> d' \left< I \land \lnot b' \right>. Il vérifie :
Exo : Annoter le programme suivant de sorte à ce qu’il soit valide :
<y >= 0>
p := 0
k := 1
while k <= y do
p := p+x
k := k + 1
done
<p = x*y>Correction :
<y >= 0>
=> <I[1/k]> *
p := 0
k := 1
<I:= p = (k-1)*x /\ k <= y+1>
while k <= y do
<I and k <= y>
=> <I[(k+1)/k][(p+x)/p]> **
p := p+x
<I[(k+1)/k]>
k := k + 1
<I>
done
<I /\ not k <= y>
=> <p = x*y> **** : \models y \geq 0 \implies 0 = (1-1)w \land 1 \leq y + 1 \square
** : \models I \land k \leq y \implies p+x=((k+1)-1)x \land k+1 \leq y + 1 \square
*** : I \land \lnot k \leq y \implies p = k x \square
\rightarrow Repartons de la logique IMP, en modifiant la structure du while.
c ::= ... | <I> while b do cet la règle associée devient :
\left< I \land b \right> c \left< I \right> \rightarrow \left< I \right> \text{while } b \text{ do } c \left< \left< I \right> I \land \lnot b \right>
Construisons maintenant une formule PO(P,c,Q) telle que : \models PO(P,c,Q) \iff \left< P \right> c \left< Q \right>
Calculons d’abors la “meilleure” précondition pour c et Q donné :
VC (Verification Condition) :
Ce qui nous donne :
PO(P, c, Q = P \implies pre(c,Q) \land VC(c,Q)
Correction: Si \models PO(P,c,Q) alors \left< P \right> c \left< Q \right>
Preuve :
On procède par induction sur c :
Cas c = x := e
Alors pre(c,Q) = Q[\frac{e}{x}] donc
\left< prec(c,Q) \right> c \left< Q
\right>
Cas c = \left< I \right> \text{
while } b \text{ do } c' :
Alors pre(c,Q) = I. Mq \left< I \right> c \left< Q
\right> :
|= I /\ b => pre(c', I) (a) <pre(c', I)> c' <I> (b)
-----------------------------------------------------
<I /\ b> c' <I>
------------------------------------------------------------
<I> <I> while b do b' <I /\ not b> |= I /\ not b => Q (c)
------------------------------------------------------------
<I> <I> while b do c' <Q>Complétude: Si \left< P \right> c \left< Q \right> Alors \models PO(P,c,Q)
On le prouve à l’aide de 2 lemmes intermédiaires :
Complétude 1: Si \left< P \right> c \left< Q \right> Alors \models P \implies pre(c,Q)
Preuve par induction sur \left< P \right> c \left< Q \right> :
\left< A \right> c_1 \left< B \right> donc \models A \implies pre(c_1, B) par HI.
\left< B \right> c_2 \left< C \right> donc \models B \implies pre(c_2, C) par HI.
Monotonie de pre
Pour tout c, Q_1, Q_2, si \models Q_1 \implies Q_2, alors \models pre(c, Q_1) \implies pre(c, Q_2).
Comme on a \models A \implies pre(c_1, pre(c_2, Q) et \models pre(c_1, B) \implies pre(c_1, pre(c_2, C)) par def, d’après le lemme précédent, \models A \implies pre(c_1;c_2, Q).
Ce lemme quant à lui se montre par induction sur c :
Cas c = c_1;c_2 :
D’après H_2, \models pre(c_2, Q_1) \implies pre(c_2, Q_2), et d’après H_1, \models pre(c_1, pre(c_2, Q_1)) \implies pre(c_1, pre(c_2, Q_2)).
Cas c = \text{x := e} : \forall Q_1, Q_2, si \models Q_1 \implies Q_2 alors \models Q_1[\frac{e}{x}] \implies Q_2[\frac{e}{x}].
Or, (lemme dont la preuve est laissée au lecteur) :
M, I \models F[\frac{e}{x}] \iff M,I[x \mapsto I(e)] \models F
Donc pour tout M :
Donc \models Q_1[] \implies Q_2[]
Complétude 2: Si \left< P \right> c \left< Q \right> Alors \models P \implies VC(c,Q)
Encore une fois, on procède par induction sur \left< P \right> c \left< Q \right> :
Cas c = \left< I \right>
\text{while } b \text{ do } c :
On a P = I, Q
= I \land \lnot b.
TODO \models VC(c', I) \left< I \land b \right> c' \left< I \right>.
Il faut prouver :
(CF cours de logique aussi).
T \models F signifie, F est valide (universellement) dans la théorie T.
On appelle théorie des axiomes (sous forme close), et une signature (symboles de fonctions et de prédicats).
La théorie vide n’a pas d’axiomes, et une infinité de symboles.
On appelle problème SAT le pb consistant en :
Ce pb est NP complet.
Cependant, les solveurs SAT résolvent des pb à en gros 100 variables et 1000 clauses en quelques minutes.
Naivement, on pourrait essayer de faire du brute force avec une table de vérité… Mais c’est mauvais même en pratique.
Il s’agit de l’algorithme de Davis–Putnam–Logemann–Loveland. Il procède par backtracking et usage d’heuristiques.
Fonctionnement
On se donne un état, consistant en une pile de couples (littéral, statut décidé / propagé) (on peut le voir comme un modèle partiel).
À chaque étape, l’algorithme va assigner une valeur au littéral courant, simplifier la formule et vérifier si elle est satisfiable. Si c’est le cas, il renvoit vrai, sinon, il backtrack, jusqu’à avoir parcouru l’ensemble des possibles.
Par rapport à un backtracking classique, DPLL va appliquer à chaque étape les actions suivantes de sorte à optimiser les performances :
On peut le formaliser de la manière suivante sous forme de transitions avec la pile :
Avec la notation : l^D signifie : on est en train de décider le littéral l.
RQ : Il reste un partie difficile… C’est de faire 2) efficacement.
Cet algorithme est souvent plus efficace dans l’ellagage que DPLL.
Il se base sur le même principe que DPLL, mais par rapport à ce dernier :
Ce qui nous donne :
RQ 1 : Truc difficile : Comment choisir C ? CF cours logique L3.
RQ 2 : On peut séparer la règle de Backjump en 2 :
Exemple d’application :
\begin{aligned} F &= (c_1 := a \lor b)\\ &\land (c_2 := a \lor \lnot b)\\ &\land (c_3 := \lnot a \lor c \lor d)\\ &\land (c_4 := \lnot a \lor c \lor \lnot d)\\ &\land (c_5 := \lnot a \lor \lnot c \lor d)\\ &\land (c_6 := \lnot a \land \lnot c \lor \lnot d)\\ &\end{aligned}
| M | F | Règle |
|---|---|---|
| \emptyset | F | \text{Decide} (a) |
| a^D | F | \text{Decide} (c) |
| a^D c^D | F | \text{UnitProp} (c_5, d) |
| a^D c^D d | F | \text{BackJump} (\lnot a, \lnot c) |
| a^D \lnot c | F \land (c_7 := \lnot a \lor \lnot c) | \text{UnitProp} (c_3, d) |
| a^D \lnot c d | F \land c_7 | \text{BackJump} (\top, \lnot a) |
| \lnot a | F \land c_7 \land (c_8 := \lnot a) | \text{UnitProp} (c_1, b) |
| \lnot a b | \text{UNSAT} | \text{Fail} (c_2) |
Solveur de théorie : pour répondre au pb, \left< F | T \models F \right>
Notation : / Q : Quantifiée. / QF : pas quantifiée.
| Théorie | Décidable ? | Complexité | RQ |
|---|---|---|---|
| FOL | NON | ||
| Eq / Q | NON | Théorie de l’égalité | |
| Eq / QF | OUI | ~ linéaire | |
| EUF / Q | NON | Eq + Congruence : \forall xny, x = y \implies f x = f y | |
| EUF / QF | OUI | n \log n | |
| Peano | NON | ||
| Presburger | OUI | NP complet | (peano sans le *) |
| Réels | OUI | O(2^{2^k |F|}) | |
| Arithméique Linéaire Rationelle | OUI | O(2^n) (simplex) | (+, -, =, \leq, sur \mathbb{Q}) |
| Tableaux* / Q | NON | =, store, get | |
| Tableaux* / QF | OUI | NP complet | =, store, get |
* : 3 axiomes :
On se base sur des formules CNF : il existe une transformation linéaire (de Tseitin) qui transforme une formule F en une formule CNF F_{CNF} qui lui est équisatisfiable.
Exemple :
\begin{aligned} F &= (P := g(a) = c)\\ &\land ((\lnot Q := f(g(a))) \neq f(c)) \lor (M := g(a = d))\\ &\land (\lnot S := c \neq d) \end{aligned}
On utilise une abstraction booléenne :
D’où : \alpha(F) := p \land q \land (\lnot q \lor r) \land \lnot s
On ajoute alors les contraintes encodant (partiellemen) les axiomes de la théorie (ici EUF) :
Et on donne au solveur SAT : H_1 \land H_2 \land \alpha(F), qui prouve UNSAT.
On conserve l’idée d’abstraction booléenne \alpha, mais on va chercher à avoir une interaction plus fine.
On introduit la transformation inverse de \alpha, \gamma (aussi appelée concrétisation).
Exemple : On reprend celui de la combinaison eager.
M_1 := p \land \lnot q \land \lnot r \land \lnot s
\gamma (M_1) := g(a) = c \land f(g(a)) \neq f(c) \land g(a) \neq d \land c \neq d
Mais un SAT solveur ne donne en général qu’un modèle booléen dans le cas SAT. Pour le forcer à tout donner, on peut :
Si il nous donne un modèle M, ajouter \lnot M à la formule, et recommencer jusqu’à UNSAT.
RQ : On peut aussi (évidemment) utiliser CDCL.
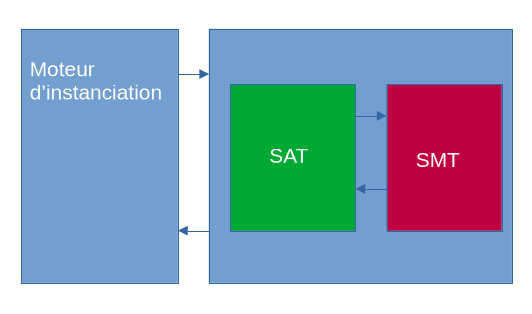
On crée une boucle d’instanciation entre DPLL et le solveur de théorie.
RQ : Ce tableau ce lit de gauche à droite, de bas en haut. On peut voir ça de la manière suivante :
Et cela jusqu’à ce que DPLL soit UNSAT.
| DPLL | EUF |
|---|---|
| \alpha(F) = p \land (\lnot q \lor r) \land \lnot s | p \land q \land \lnot s, puis via \gamma : g(a) = c \land f(g(a)) \neq f(c) \land c \neq d, puis via EUF UNSAT : g(a) = c \land f(g(a)) \neq f(c) =: p \land \lnot q |
| F_ 1 = F \land (\lnot p \lor q) | p \land q \land r \land \lnot s =: M_3, puis via \gamma : … puis via EUF UNSAT : g(a) = c \land g(a) = d \land c \neq d =: p r s |
| F_2 = F_1 \land (\lnot p \lor \lnot r \lor s ) qui est UNSAT : fin |
Plus précisément :
Cela nous donne les règles suivante pour notre algorithme :
| Règle | Transition | Condition |
|---|---|---|
| \text{Decide}(l) | (M,F) \rightarrow (Ml^D, F) | l indéfini dans M |
| \text{UnitProp}(C,l) | (M,F) \rightarrow (Ml, F) | C \lor l \in \alpha(F), M \models \lnot C, l indéfini dans M |
| \text{Learn}(C) | (M,F) \rightarrow (M, F \land \gamma(C)) | \alpha(F) \models C |
| \text{Backjump}(C, l') | (M_1 l^D M_2,F) \rightarrow (M_1 l', F) | C \lor l' \in \alpha(F), M_1 \models \lnot C, l' indéfini dans M |
| \text{Fail}(C) | (M,F) \rightarrow \text{UNSAT} | C \in \alpha(F), M \models \lnot C, M sans décision, \gamma(M) \models_T \lnot \gamma(C) |
| $ | (M,F) \rightarrow \text{SAT} | M \models \alpha(F), \gamma(M) est T - \text{SAT} |
| \text{T - Conflict}(C) | (M,F) \rightarrow (M, F \land C) | \models_T C, M \models \lnot \alpha(C) |
| \text{T - Propagation}(l) (Optimisation) | (M,F) \rightarrow (Ml, F) | \gamma(M) \models_T \gamma(l), l indéfini dans M |
Exemple (on reprend la formule F) :
Trace de \text{DPLL}(T) :
| M | F | Transition | Condition |
|---|---|---|---|
| \emptyset | F | \text{UnitProp}(C_1, p) | |
| p | F | \text{UnitProp}(C_3, \lnot s) | |
| p \lnot s | F | \text{T-Propagate}(q) | \gamma(p \land \lnot s) \models \gamma (q) |
| p \lnot s q | F | \text{UnitProp}(C_2, r) | M \models q |
| p \lnot s q r | F \land C_3 | \text{UnitProp}(C_1, p) | M \models \alpha(\lnot (C_4^T := \gamma(\lnot p \lor \lnot q \lor s))), \models C_4 |
| p \lnot s q r | F \land C_4^T | \text{Fail}(C_4^T), C_4 = \alpha(C_4^T) | C_4 \in \alpha(F \land C_4^T), M \models \lnot C_4, M sans décision, \gamma(M) \models_T \lnot \gamma(C_4) |
RQ : Les règles de Backjump et
Fail n’ont pas besoin de T-solveur, car on sait déjà : M \models \lnot C.
Le T-solveur n’est utilise que
T-propagate et T-conflict.
Reprenons par ailleurs l’exemple, sans T-propagate pour
montrer l’optimisation qu’elle apporte.
| M | F | Règle | Justification |
|---|---|---|---|
| \emptyset | F | \text{UnitProp}(C_1, p) | |
| p | F | \text{UnitProp}(C_4, \lnot s) | |
| p \lnot s | F | \text{Decide}(\lnot q) | |
| p \lnot s (\lnot q)^D | F | \text{T-conflict}() | \gamma(p \land \lnot s \land \not q) \equiv g(a) = c \land c \neq d \land f(g(a)) \neq f(c), donc C_4^T=g(a) \neq c \lor f(g(a)) = f(c), et \models_T C_4^T, M \models \lnot p \lor q, C_4 = \alpha(C_4^T) |
| p \lnot s {\lnot q}^D | F \land C_4^T | \text{Backjump}(\lnot p, q) | C = \lnot p, p \models \lnot C, C \in F \land C |
| p \lnot s q | F \land C_4^T | \text{UnitProp}(C_2, r) | C \in F \land C |
| p \lnot s q r | F \land C_4^T | \text{T-conflict}() | C_5^T = \gamma(C_5), C_5 = \lnot p \lor \lnot a \lor s, \models_T C_5^T, M \models C_5 |
| p \lnot s q r | F \land C_4^T \land C_5^T | \text{Fail}(C_5^T) | M \models \lnot C_5 |
RQ : On ne peut cependant pas se passer de
T-conflict.
On a vu que dans un SMT solveur, on s’intéressait à combiner un SAT solveur avec un solveur de théorie.
Aujourd’hui, on va s’intéresser à une théorie particulière, la théorie EUF (Equality + Uninterpreted Functions).
Langage EUF :
Exemple de formules : \forall x,y, f(x) = g(y) \implies g(x) = f(y)
Ici, on se restreint à QFEUF (Quantifier Free EUF).
Axiomes d’EUF :
Réflexivité : \forall t, t = t
Symmétrie : \forall t,u, t = u \implies u = t
Transitivité : \forall t_1, t_2, t_3, (t_1 = t_2 \land t_2 = t_3) \implies t_1 = t_3
Congruences : $k , $ Ou, en français : “Pour tout entier k, si h est une fonction d’arité k, alors si les sous atomes distincts de deux h-termes sont égaux deux à deux, alors les h-termes sont égaux.”
Ex, pour f unaire : \forall t,u, t = u \implies f(t) = f(u)
Un monome est une formule CNF de EUF.
Idée : On recherche la cloture par congruence de égalités du monome c’est à dire la plus petite relation de congruence qui contient ces égalités.
Ingrédients :
On appelle e-graph un graphe orienté biparti G = ((N,C), E).
Ses sommets sont bipartis en N l’ensemble des e-nodes et C l’ensemble des e-classes.
Un e-graph G = ((N,C), E) représente un ensemble de termes Rep(G) :
RQ : Un terme t \in Rep(G) est représenté par une unique e-classe et un unique e-node.
Un e-graphe affiche l’interface suivante :
add qui prend en entrée un terme t.
Algo :
ADD(Terme h(t1,...tk)) :
pour i allant de 1 à k :
ci = ADD(ti)
si N contient l'Enode h(c1,...ck) :
renvoie la classe correspondante
sinon :
ajoute h(c1, ..., ck) à N
ajoute une nouvelle Eclasse c à C
ajoute (c, h(c1,...,ck)) à E
renvoie cmerge prend en entrée deux eclasses c_1 et c_2, et les fusionne. Algo :
MERGE(Eclass c1, Eclass c2) :
si c1 = c2:
return # RAF
Pour chaque Enode n in c2 :
remplacer (c2, n) par (c1, n) dans E
Pour chaque parent p = h(..., c2) :
remplacer (p, c2) par (p, c1) dans E
Pour chaque parent p de c1 :
Pour chaque autre parent p' de c1 :
Si p et p' ont le même symbole et ont les mêmes arcs sortants (dans le même ordre) :
c = classe de p
c' = classe de p'
supprimer p' de l'Egraph
MERGE(c,c')On a alors une procédure de décision QFEUF :
DECIDE_QFEUF(Monome m) :
créer un Egraph vide G
pour chaque égalité t = u dans m :
c1 = ADD(t)
c2 = ADD(u)
MERGE(c1,c2)
pour chaque inégalité t != u dans m :
c1 = ADD(t)
c2 = ADD(u)
si c1 = c2 : renvoyer UNSAT
renvoyer SATCette procédure est correcte et complète.
Idée : On essaie de se ramener à des formules sans quantificateurs ?
Dans certaines théorie, il existe une procédure pour transformer toute formule \Phi en une formule \tilde{\Phi} équisatisfiable. Ces procédures n’existe pas dans le cas général, et sont souvent couteuses en calculs.
Cependant, pour montrer qu’une formule quantifiée est UNSAT, on peut juste exiber un contre exemple. Autrement trouver une instatiation des variables quantifiées qui la transforme en formule non quantifiée UNSAT, ce qui est calculable. On va donc essayer, dans la suite, de trouver une “bonne” instantiation.
On commence par se placer dans un cas d’étude restreint :
On considère les formules de la forme Q \land U où Q est une conjonction de formules avec quantificateurs et U est une CNF à formules sans quantificateurs.
On le fait sans perte de généralité.
Dans Q on élimine les implications et on pousse les négations aux feuilles.
Pour toute sous formule existencielle \exists x, \Phi(x) dans Q, on skolémise : On introduit un nouveau symbole e_x dans le langage et on remplace \exists x, \Phi(x) par \Phi(e_x).
/!\ : \forall x, \exists y, P(x,y) devient : \forall x, P(x, f_y(x))
Cela nous donne une formule équisatisfiable (cf cours de logique du premier ordre).
Mise sous forme PCNF (Prenex CNF).
- On renomme les variables liées au \forall pour que chaque \forall ait sa variable unique.
- On fait remonter les \forall à la
racine de la formule. - On obtient ainsi une formule équisatisfiable
\forall x, y, z, ..., \Phi(x,y,z,...).
On met \Phi en forme CNF.
On se ramène à une formule Q \land U où U est une CNF sans quantificateurs (appelée faits de base) et Q est une conjonction de formules PCNF (on pourrait juste avoir une PCNF, mais pas très utile) appelée les universelles.
On va donc devoir utiliser un moteur d’instantiation pour tenter d’instancier les variables quantifiées universellements, pour la satisfiabilité :
Défi : Comment trouver les instanciations pertinentes ?
Idée naïve : Essayer tout les termes de U.
Instantiation par déclencheur (trigger) : Pour toute universelles, \forall x, ..., z, \Phi(x, ..., z) de Q. On sélectionne un déclencheur p(x, ..., z)
Fonctionnement : Si on observe dans U une instantiation p(t_x, ..., t_z) du déclencheur p, alors on ajoute \Phi(t_x, ..., t_z) aux faits de base.
Exp :
RQ (choix du déclencheur) :
Le procédé de matching : recherche dans U des instanciations pour nos déclencheur.
En pratique, on stocke U dans un e-graph (car les théorie sont souvent dotées de la congruence).
Les e-graph proposent alors une opération nommée e-matching, adaptée à la recherche d’instanciations de déclencheurs.
Notations :
Soit c \in C une e-clause et v une substitution. On dit que c,v est une occurence de p dans l’e-graph si :
\{ p(t_x, ..., t_y) | \forall y \in Free(p), t_y \in Rep(\sigma(y)) \} \subseteq Repr(c)
Procédé d’e-matching :
Ici, on va s’intéresser à des formules particulières :
On cherche à résoudre le problème suivant :
T_{LRA} := \{F | F_{SAT}\}
Ce problème est polynomial par programmation linéaire, d’après Dantzig (1947).
On peut toujours représenter une instance de T_{LRA} par M = (A,B,N,(e_i), (u_i)) avec :
telle que :
F \in T_{LRA} équivalent à l’existence d’ube solution pour le problème S_M suivant :
On défini un état de l’algorithme par :
Invariants :
On prend l’algorithme suivant :
L’état initial est \beta(_) = 0.
Tant que exists x_i in B, tq beta(x_i) < e_i ou beta(x_i) > u_i :
SI on détecte S_M = vide : Renvoie UNSAT
SINON : choisir x_j in N tel que :
(M', beta') = PIVOT(M, beta, x_i, x_j)
M', beta' satisfait (I_1) et (I_2) et S_M = vide <=> S_m' = videL’invariant est initialement vrai.
Démo :
Exemple :
N = \{x, y\}, B = \{s_1, s_2, s_3\}, \beta = 0
1er test de boucle :
\rightarrow \beta ne satisfait pas 2 \leq \beta(s_1). On veut “augmenter” \beta(s_1) jusqu’à 2, et on va permuter s_1 et x dans B et N.
Pivot de Gauss :
On exprime x en fonction de s_1 :
(M, \beta) \leftarrow (M', \beta').
2e test de boucle :
\rightarrow il faut augmenter \beta(s_3) : -2 \rightarrow^{+3} 1
En augmentant \beta(y) de 1 :
Pivot de Gauss :
s_3 \leftrightarrow y
Alors :
Donc B = \{x, s_2, y\}, N = \{s_1, s_3\}
3e test de boucle :
FIN : F est SAT pour x = 1, y = 1
Considérons F = (A_1 := f(f(x) - f(y))) \neq f(z) \land x < z \land y + z \leq x \land 0 \leq z
On se situe dans la théorie des fonctions non interprétées, donc pas LRA, et pas EUF car il n’y pas que des inégalités.
La méthode de Nelson Oppen permet alors de créer une théorie que l’on peut utiliser pour résoudre ce problème, en en réutilisant (et plus précisément en en combinant) des déjà connues. La théorie finale utilisée sera la théorie union.
/!\ : Limitation : Les théories considérées doivent être à signature disjointe.
Sépare F en sous formules pures.
Soit F une conjonction de littéraux sur la signature \Sigma_1 \cup \Sigma_2 avec \Sigma_1 \cap \Sigma_2 = \{ = \}
On appelle purification de F les deux conjonctions :
telles que F et F_1 \land F_2 soient équisatisfiables.
Procédé :
La purification peut se faire de la manière suivante. Pour chaque sous terme de T_1 qui apparait dans un terme de T_2, on instancie une variable fraiche et une égalité.
Exemple sur le F de la motivation :
Le reste ne change pas, on obtient donc :
On peut alors créer un algorithme résolvant notre problème initial :
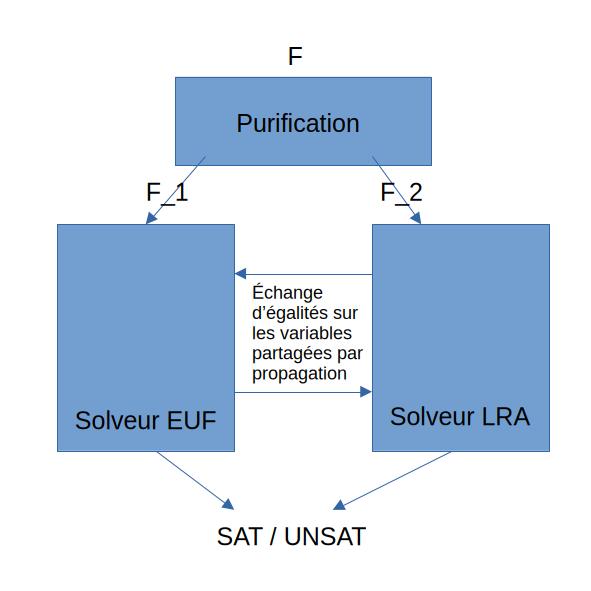
Nelson-Oppen(F):
F1,F2 <- Purification(F)
T1.assume(F1)
T2.assume(F2)
Tant que T1.sat() ou T2.sat() :
Si il existe i,x,y tq Ti.propagate() equiv x=y:
j <- 2 - i
Tj.assume(x = y)
Sinon renvoie SAT
renvoie UNSATExemple :
| Étape | EUF | LRA |
|---|---|---|
| 0 | u = f(x), v = f(y), f(w) \neq f(z) | w = u - v, x \leq y, y + z \leq x, 0 \leq z |
| 1 | déduit x = y | |
| 2 | reçoit x = y | |
| 3 | déduit u = v | |
| 4 | reçoit u = v | |
| 5 | déduit w = z | |
| 6 | reçoit w = z, UNSAT |
Étape 0 : y + 0 \leq y + z \leq x \leq y donc x = y
Étape 5 : u = v donc w = 0 et x = y donc z = 0. Donc x = z
/!\ : On ne communique que des égalités entre variables, donc pas w = 0 par exemple !
Pour montrer la correction et la complètude de cet algorithme, on introduit la notion de convexité de théorie :
Une théorie T est dite convexe si, pour toute conjonction de littéraux F et toute disjonction d’égalité \lor_{i=1}^n x_i = y_i :
Si F \models_T D, alors \exists i, F \models_T x_i = y_i
Exemples :
Si les théories T_1(\Sigma_1) et T_2(\Sigma_2) vérifient :
Alors Nelson-Oppen est correct et complet.
Exemple de théorie non totalement infinie :
E \mapsto F est vraie dans l’état (s,h) ssi :
E,s \Downarrow l \in Loc F,s \Downarrow v \in Val
dom(h) = \right< l \left>, h(l) = v
(s, h) \models emp ssi h est vide.
P \ast Q est vraie dans (s,h) ssi il existe deux tas h_1 et h_2 tels que :
Remarque : emp est neutre pour \ast.
On notera aussi : E \mapsto F_0, ..., F_n \equiv E \mapsto F_0 \ast E + 1 \mapsto F_1 \ast ... \ast E + n \mapsto F_n
Soit \alpha une liste mathématique dans \cup_n Exp^n.
On définit de manière inductive (s, l) \models list(\alpha, e) :