
2026 - 03 - 25
Un peu d’histoire : Un grand nom, Claude Shannon.
En 1948, 2 grands théorèmes :
On appelle source d’information des variables aléatoires (X_1, X_2, ...) de loi commune \mathbb{P}_X. Alors, X_i : (\Omega, \mathbb{P}) \rightarrow (H, \mathbb{P}_X). On appelle X une machine qui produit un échantillon x \in H selon \mathbb{P}_X
On remarque qu’un evênement rare contient beaucoup d’information, portée par l’évênement.
On appelle borne de compression le nombre minimal de bits nécessaires pour représenter X sans erreur, en moyenne.
1er théorème de Shannon : La borne de compression se calcule uniquement en fonction de \mathbb{P}_X.
On appelle canal bruité une fonction transformant X en Y, qui suit une loi Y|X de même entrée et sortie mais avec un proba différente.
Quelle redondance ajouter pour une transmission fiable ?
On appelle rendement \rho d’un code correcteur la valeur \frac{k}{k+m}, si on rajoute m bits pour corriger les erreurs d’un message à k bits.
On appelle probabilité résiduelle la probabilité de faire un erreur après “encodage” et “décodage” correcteur.
On appelle capacité C du canal le rendement maximal qu’il est possible d’atteindre pour transmettre sans erreur sur un canal bruité.
2é théorème de Shannon : On peut transmettre à rendement r \leq C sans erreur asymptotiquement. De plus, C = f(\mathbb{P}_{Y|X}).
/!\ Asymptotiquement :
Jusqu’en 1993, on a pas d’algo atteignant C. Puis, turbo code par Alain Glavieux et Claude Berrou qui s’en place très proche.
Mais il y avait des brevets dessus…
Bob Gallager : LDPC (Low Density Parity Check) (avec suffisament de bits à encoder).
Convention pour la suite : \log 0 = 0
On considère une source d’information X : (\Omega, \mathbb{P}) \rightarrow (\mathcal{X}, \mathbb{P}_\mathcal{X})
Comment décrire, par exemple (ici en info), la source C : \mathcal{X} \rightarrow {0,1}^* ?
Le but est de trouver un code optimal, e.g. qui minimise \mathbb{E}_{\mathbb{P}_\mathcal{X}}(|C(X)|) = \sum_{x \in \mathcal{X}} |C(x)|\mathbb{P}_\mathcal{X}(x)
Notation : pour simplifier par la suite, on note p_x := \mathbb{P}_\mathcal{X}(x)
On appelle \mathcal{X} un ensemble de symbole, et un de ses éléments un symbole.
Idée : On associe -\log_2 p_x bits au symbole x.
On appelle entropie de la source X, notée H(X), la valeur donnée par : H(X) = - \sum_{x \in \mathcal{X}} p_x \log_2 p_x = \mathbb{E}_{\mathbb{P}_\mathcal{X}} (- \log_2 p_x)
Quelques propriétés de l’entropie :
Preuve : par optimisation sous contraintes (multiplicateurs de lagrange), en faisant attention aux bords.
H(X| Y = y) = - \sum_x p_{x|y} \log_2 p_{x|y}
On fixe Y à la valeur y, et on calcule l’entropie sur X pour Y = y.
Entropie conditionelle de X sachant Y : H(X| Y) = - \sum_y p_{y} H(X|Y=y)
RQ : H(X|Y) mesure l’incertitude restant sur X lorque Y est connue ou encore le nb de bits manquant pour donner X quand on nous révèle Y.
Preuve du 3e point :
\begin{aligned} H(X, Y) &= - \sum_{x,y} p_{x,y} \log_2 p_{x,y}\\ &= - \sum_{x,y} p_x p_{y|x} \log_2 (p_{x} p_{y | x})\\ &= - \sum_{x,y} p_x p_{y|x} (\log_2 p_{x} + \log_2 p_{y | x})\\ &= - \sum_{x,y} p_x p_{y|x} \log_2 p_{x} - \sum_{x,y} p_x p_{y|x} \log_2 p_{y | x}\\ &= - \sum_{x,y} p_x p_{y|x} \log_2 p_{x} + H(Y|X)\\ &= - \sum_{x} p_x \log_2 p_x (\sum_{y} p_{y|x}) + H(Y|X)\\ &= - \sum_{x} p_x \log_2 p_x + H(Y|X)\\ &= H(X) + H(Y|X)\\ \end{aligned}
Généralisation : On peut ainsi déterminer pour n variables.
On note I(X;Y) := H(X,Y) - H(X|Y) - H(Y|X)
Pour raisonner, on peut aussi utiliser des diagrammes de Venn :
Imaginons qu’on encode X \sim p_x.
Si on suppose la distribution q_x sur X, alors à x on attribue -\log_2 q_x bits.
On en consomme donc :
- \sum_x p_x \log_2 q_x / symbole en moyenne (on appelle ça l’entropie relative).
Est ce efficace par rapport à la vraie loi de X, e.g. combien on perd de bits ?
Si on mesure la différence avec H(X), on obtient :
\begin{aligned} \Delta &= -\sum_x p_x \log_2 q_x - (- \sum_x p_x \log_2 p_x)\\ &= \sum_x p_x \log_2 \frac{p_x}{q_x} \end{aligned}
On définit donc :
On note D(p||q) := \sum_x p_x \log_2 \frac{p_x}{q_x} (aussi notée D_{KL}, KL(p||q), KL(p,q)) la divergence de Kullback-Leibler.
RQ : En machine learning, deux approches :
L’information mutuelle entre les V.A. X et Y est définie par I(X;Y) := H(X,Y) - H(X|Y) - H(Y|X)
On définit l’entropie mutuelle conditionelle entre X et Y sachant Z par :
\begin{aligned} I(X;Y|Z) &:= D(p_{x,y|z}||P_{X|Z} \otimes P_{Y|Z})\\ &= \sum_z p_z I(X;Y|Z=z)\\ &= \sum_z p_z \sum_{x,y} p_{x,y|z} \log_2 \frac{p_{x,y|z}}{p_{x|z} p_{y|z}}\\ &= \sum_{x,y,z} p_{x,y,z} \log_2 \frac{p_{x,y|z}}{p_{x|z} p_{y|z}} \end{aligned}
/!\ Le conditionnement ne réduit pas l’information mutuelle !
Soit X_n un processus stochastique à temps discret, e.g une suite de V.A.
(X_n) est une chaine de markov ssi :
$n, k q, $
On a donc, pour une chaine de Markov X_n : P_{X_1,...X_n} = P_{X_1} P_{X_2 | X_1} ... P_{X_n | X_{n-1}}
DPI : si X \rightarrow Y \rightarrow Z forme une chaine de Markov, alors I(X;Y) \geq I(X;Z)
Interpretation : plus on s’éloigne de l’origine X_1, moins on a d’information commune avec elle (on “oublie”).
Consequence :
RQ : En diagramme de Venn, on peut voir une chaine de Markov comme une suite de carrés glissants.
Soit p et q deux distributions pour la V.A. Y sur \mathcal{Y}.
Alors on definit l’enthropie croisée (ou cross-enthropy) : H(p,q) = - \sum_{y} p_y \log_2 q_y
Interprétation
Si la loi de Y est p, on attribue à Y une budget de -\log_2 bits pour la décrire. Si on se “trompe” de distribution, on prend q à la place de p \rightarrow Y est décrite avec - \log_2 q_y bits.
On utilise alors en moyenne H(p,q) bits / symbole, au lieu de H(p) : c’est moins efficace, on perd exactement D(p||q) bits par symbole.
Application 1
Dans bcp de problèmes, p est inconnue (dépend d’autres données) / est irrégulière (e.g. trop complexe). Cependant, on dispose quand même d’un (long) échantillon y_1, ..., y_n.
On cherche une distribution q sur \mathcal{Y} qui approxime p et qui est structurée : q \in \mathcal{E} avec \mathcal{E} un espace paramétré.
On veut trouver \min_{q \in \mathcal{E}} D_{KL} (p||q).
\Leftrightarrow \min_{q \in \mathcal{E}} H(p,q) = \mathbb{E}_p (-\log_2 q_y) car H(p) est fixé.
PB : On a pas p pour calculer cette espérance ! On remplace donc p par la loi empirique \hat{p} calculée les données y_1, ... y_n, càd que l’on cherche : \min_{q \in \mathcal{E}} \frac{1}{n} \sum_{i = 1}^n -\log_2 q_y.
Application 2
On veut entrainer un classifieur.
On suppose qu’on a une paire de V.A. (X, Y), (par exemple, X est l’ensemble d’image, et Y l’ensemble des classes).
P_{X,Y} est inconnue, mais on a un ensemble d’exemples (x_1, y_1), ..., (x_n, y_n).
P_X est inconnue et inaccessible, et P_{Y|X} est idéalement déterministe. Cela reste vrai si on regarde la loi empirique \hat{P_{Y|X}}
On veut entrainer un classifieur f_\theta : \mathcal{H} \rightarrow \mathcal{D}(\mathcal{Y}), x \mapsto f_\theta (\cdot | x) où f_\theta (y | x) est la proba de la classe y associée à l’image x
Pour x \in \mathcal{H}, le critère à optimiser est H(P_{Y|X = x}, f_\theta (\cdot | x)). On moyenne sur X, on cherche donc : \min_{\theta} -\sum_x p_x \sum_y p_{y|x} \log_2 f_\theta (y | x) remplacé par \min_\theta - \frac{1}{n} \sum_{i=1}^n \log_2 f_\theta (y_i | x_i)
Soit (X_i)_{i \in \mathbb{N}} une suite de V.A. identiques et indépendantes \sim P_X, à valeurs dans \mathcal{H}.
Soit x_1, ..., x_n \in \mathcal{H}^n séquence de n valeurs de X_1, ..., X_n probabilité empirique issue de l’échantillon x_1...x_n aussi noté x_1^n.
\forall a \in \mathcal{H}, \pi(a|x_1^n) = \frac{1}{n} \sum_{i=1}^n \mathbb{1}_a(x_i) = \frac{1}{n} \#_a(x_1,...,x_n).
Loi faible des grands nombres (LfGN) :
\pi(a|x_1...x_n) \rightarrow_n^\mathbb{P} P_X(a), càd : \forall \eta > 0, \mathbb{P} (|\pi(a|X_1,..., X_n) - \mathbb{P}_X(a)| < \eta) \rightarrow_n 1
x_1,...,x_n \in \mathcal{H}^n est fortement typique pour \epsilon ssi : \forall a \in \mathcal{H}, |\pi(a|x_1,...,x_n) - \mathbb{P}(X=a)| \leq \epsilon \mathcal{P} (X = a)
A_\epsilon^n = ensemble des séquences x_1,...x_n fortement typiques pour \epsilon.
Rem : Si \mathbb{P}_X(a), x_1,...,x_n fortement typique \implies \pi(a|x_1,...,x_n) = 0
Soit g : \mathcal{H} \rightarrow \mathbb{R}^+, x_1,...,x_n \in A_\epsilon^n. Alors, (1- \epsilon) \mathbb{E}(g(x)) \leq \frac{1}{n} \sum_{i=1}^n g(x_i) \leq (1 + \epsilon) \mathbb{E}(g(X))
Soit x_1^n \in A_\epsilon^n, alors (1 - \epsilon) H(x) \leq -\frac{1}{n} \log_2 p(x_1,...,x_n) \leq (1 + \epsilon) H(X), ou encore : 2^{-n H(X) (1 + \epsilon)} \leq p(x_1,...,x_n) \leq 2^{-n H(X) (1 - \epsilon)}
Rem : Cette propriété pourrait être choisie pour définir la typicalité (faible).
\lim_{n \to \infty} \mathbb{P}(X_1^n \in A_\epsilon^n) = 1
(AEP, Asymptotic Equipartition Property)
Pour n grand, \mathbb{P}(A_\epsilon^n) \simeq 1, contient \simeq 2^{n H(X)} séquences typiques, chacune de vraisemblance p(e_1,...,e_n \simeq 2^{-n H(X)}).
\implies tout se asse comme si X_1,...,X_n avait une distribution uniforme sur A_\epsilon^n.
Application
Quitte à encoder de longues séquences indépendantes & identiques X_1,...,X_n, on peut compresser une source X avec H(X) bits / symbole.
Méthode : Encodage par typicalité :
On considère x_1^n \in \mathcal{H}.
Et on rajoute un préfixe :
Conclusion : Ainsi, avec cet encodage par typicalité, on peut encoder une séquence avec H(X) bits / symbole.
Démo :
Soit L(x_1,...,x_n) la longueur d’encodage de x_1^n.
On appelle code pour la source X, sur \mathcal{H}, et d’alphabet \mathcal{A}, une application C : \mathcal{H} \rightarrow \mathcal{A}^+
C(x) est le mot de code associé à x.
Soit L : \mathcal{A}^+ \rightarrow \mathbb{N} la longueur d’un mot.
On veut calculer (et minimiser !) \mathbb{E}(L \circ C(X)) = \sum_x p_x l_x, où l’on pose l_x := L(C(x)).
On définit l’extension d’un code C l’application :
C : \mathcal{H}^+ \rightarrow \mathcal{A}^+; x_1...x_n \mapsto C(x_1)...C(x_n)
On dit que C est uniquement décodable ssi son extension est non singulière, càd, si pour un C(x_1...x_n) donné, on peut retrouver n, x_1, ..., x_n.
Exemple :
On dit qu’un code est préfixe si aucun C(x) n’est préfixe de C(y), pour y \neq x.
Alors, ce code est uniquement décodable.
Exercice :
Pour \mathcal{A} = \{0,1\}
Inégalité de Kroft :
Si C est un code préfixe sur \mathcal{H} = \{x_1, ..., x_n\} sur l’alphabet \mathcal{A} avec |\mathcal{A}| = D,
Alors \sum_i D^{-l_i} \leq 1 avec l_i = |C(x_i)|.
Réciproquement, si cette inégalité est vérifiée, alors il existe un code préfixe avec ces longueurs.
De manière plus générale, les codes uniquement décidables vérifient aussi cette inégalité.
Preuve :
Montrons que \sum_i D^{-l_i} \leq 1.
\begin{aligned} (\sum_i D^{-l_i})^k &= \sum_{1 \leq i_1, ..., i_k \leq N} \prod_{j = 1}^k D^{-l_i_j}\\ &= \sum_{i_1, ..., i_k} D^{-\sum_{j = 1}^k l_i_j} \\ &= \sum_{l = 1}^{k l_{max}} a(l) D^{-l} \text{où $a(l) =$ le nb de mots de code dans $\mathcal{H}^k$ de longueur $l$} \end{aligned} Comme C^k est uniquement décodable, on a au plus D^l mots de longueur l.
Donc a(l) \leq D^l.
Donc \forall k, \sum_i D^{-l_i} \leq k l_{max}
Donc avec l\rightarrow + \infty, \sum_i D^{-l_i} \leq 1 CQFD.
Idée : On cherche les longueurs des mots de code l_1, ..., l_N optimales, tq les inégalités dde Kroft soient satisfaites. On veut minimiser \sum_i p_i l_i = \mathbb{E} (L \circ C(X)), sous la contrainte \sum D^{-l_i} \leq 1.
RQ : On ignore la contrainte l_i \in \mathbb{N}.
Résolution :
\mathcal{L}(l_1,...,l_N, \lambda) = \sum_i p_i l_i + \lambda (\sum_i D^{-l_i} - 1)
KKT :
\frac{\partial \mathcal{L}}{\partial l_i} = 0 = p_i - \lambda (\log D) D^{-l_i}
Donc -l_i = \log_D \frac{p_i}{\lambda \log D} = \log_D p_i + cste.
Comme on veut de plus \sum_i D^{-l_i} = 1, on obtient \lambda = \frac{1}{\log D}
D’où l_i = - \log_D p_i
La longueur minimale est donc $(L C(X)) = _i p_i l_i = H_D (X) $
On en déduit qu’il n’existe pas de code préfixe de longueur moyenne infèrieur à H_D(X).
On appelle code de Shannon un code qui utilise \lceil -\log_2 p_i \rceil bits.
Pour un code de Shannon : H_2 (X) \leq \mathbb{E}(L \circ C(X)) < H_2 (X) + 1
Conclusion : Quitte à encode k symboles consécutifs, on peut compirmer X avec H(X) + \frac{1}{k} bits / symbole. On peut exprimer X jusqu’à H(X) bits / symbole.
Soit p_1 \geq p_2 \geq ... \geq p_N la loi de X. Soit l_1, ..., l_N les longueurs des mots de code.
Un code de Huffman vérifie :
H_D (X) \leq L_{Huff} (X) < H_D (X) + 1
On arrive donc à la même conclusion que pour les codes de Shannon.
Soient deux sources X_1, X_2. On cherche à les encoder avec un algorithme distribué (un encodeur différent pour chaque X_i, qui ne communiquent pas entre eux). (C’est un peu l’algo d’internet, et surtout du P2P).
Slepian-Wolf :
Si on note R_i le nombre de bits avec lesquels on encode la source i, alors un tel algo existe ssi :
Preuve \implies en DM.
On note \mathcal{X} les entrées du canal, et \mathcal{Y} ses sorties.
Par exemple, un canal binaire symmétrique ressemble à :
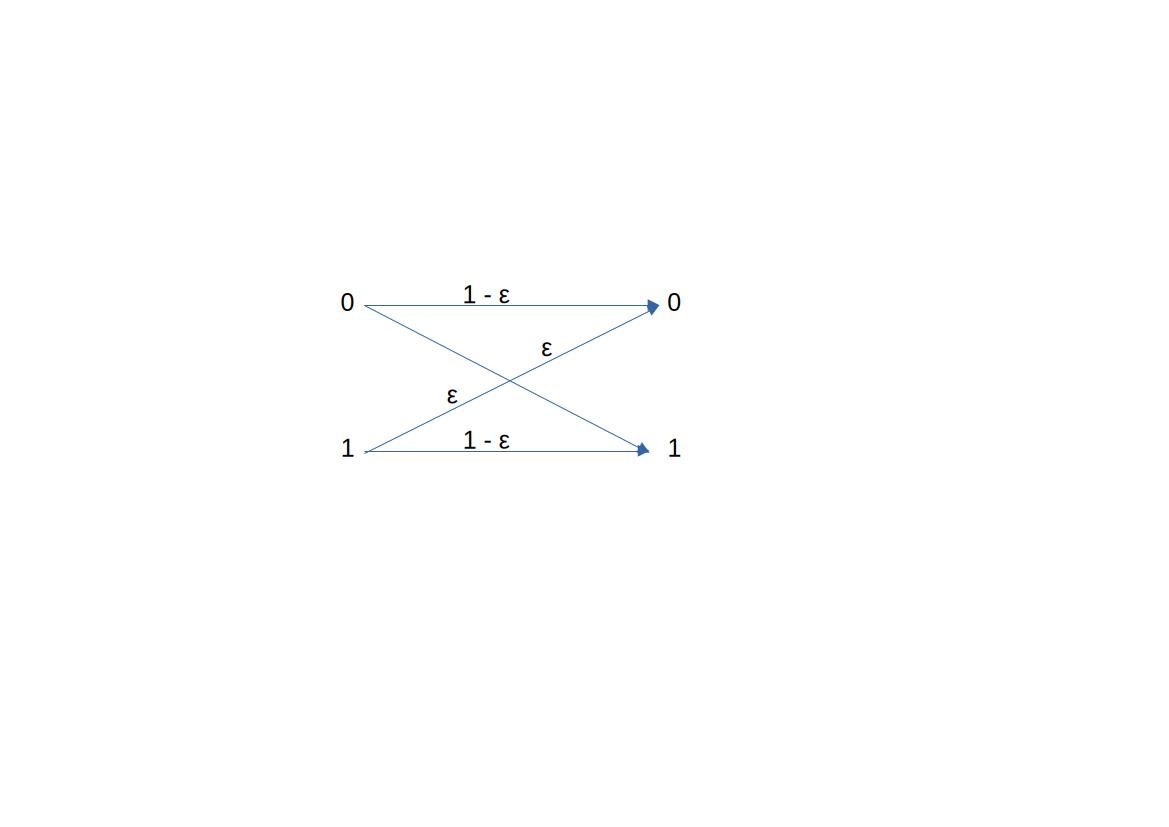
À gauche se trouve X, à droite Y, et la probabilité notée sur les flèches est P_{Y | X}.
On appelle capacité du canal C, la quantité d’information qu’on peut faire transiter sans perte dans le canal. Ici, elle vaut 1 si epsilon est égal à 0 ou 1 (car alors, la sortie est entièrement déterminée). Nous en verrons une définition plus précise dans la suite.
On a notamment C \leq min(log |\mathcal{X}|, log |\mathcal{Y}|).
Si \epsilon = 1/2, P_{Y | X = 0} = P_{Y | X = 1}, donc C = 0.
On appelle canal sans mémoire un canal tel que la transformation d’un symbole x en un symbole y ne dépende pas des transformations précédentes.
On peut le représenter par le shéma suivant :
M \rightarrow Enc \rightarrow^{X^n} (P_{Y|X}) \rightarrow^{Y^n} Dec \rightarrow \hat{M}
On note R et on appelle débit du canal le nombre tel que M \in \{1,..., 2^{nR}\}
On va alors considérer une distribution uniforme (pas de compression) pour se focaliser sur le bruit.
On dit qu’un débit R >= 0 est atteignable si :
\forall \epsilon > 0, \exists N, \forall n >= N, \exists (Enc, Dec), P(M \neq \hat{M}) \leq \epsilon, où (Enc, Dec) on une capacité R.
Borne de Shannon :
C = \max_{P_X \in \Delta(\mathcal{X})} I(X;Y) où \Delta(\mathcal{X}) est l’ensemble des distributions de probabilité sur \mathcal{X}.
RQ : Il existe un algorithme d’optimisation convexe, l’algorithme de Blahut-Arimoto, pour calculer numériquement cette borne.
Soit X, Y, Z vérifiant la propriété de chaîne de Markov : \begin{aligned} P_{XYZ} &= P_x P_{Y|X} P_{Z|XY}\\ &= P_X P_{Y|X} P_{Z|Y}\\ &= P_Z P_{Y|Z} P_{X|Y} \end{aligned}